Проектирование надежных решений
технического обслуживания
Мы продолжаем расширять кругозор наших читателей разными примерами построения эффективных систем управления ТОиР. Пищевая промышленность редко попадает в сферу внимания «настоящих механиков» из тяжеловесных энергетических и горных компаний. Но и в этой отрасли есть немало примеров, которые могут подсказать, как построить свою систему на любом предприятии.
Эффективность технического обслуживания зависит от возможности определения реальных требований к обслуживанию оборудования. Это достигается с помощью системы сбора достоверной информации о сроке службы этого оборудования и его компонентов. Выявление потенциального и функционального отказов компонентов или частей оборудования является постоянной задачей, необходимой для определения переменных, обуславливающих возникновение этих двух событий. Более того, качественный анализ отказов позволяет держать под контролем важнейшие функции систем. Недостаточный уровень системы технического обслуживания может привести к серьезным потерям и к снижению доли компании на рынке вследствие плохого качества и низкой безопасности пищевой продукции. В данной статье приведены некоторые рекомендации по созданию эффективной программы технического обслуживания и ремонта оборудования.
1. Получение информации об отказах с помощью системы анализа сообщений об отказах и корректирующих действий (Failure Reporting Analysis and Corrective Action System — FRACAS)
FRACAS — это система непрерывного совершенствования, использующая замкнутый контур обратной связи, в которой регистрируются данные отказов активов/оборудования. Затем эти данные критически оцениваются и анализируются с учетом таких факторов, как интенсивность отказов (Failure Rate), средняя наработка до отказа (MTBF), среднее время до восстановления (MTTR), готовность (Availability), стоимость (Cost) и т.д. Эта система должна быть внедрена и верифицирована для предотвращения повторения будущих отказов.
Инструмент FRACAS особенно полезен для выявления потенциальных и функциональных отказов с учетом их влияния на безопасность пищевой продукции и затрат компании. Система FRACAS может управлять множеством отчетов об отказах, сформированных большим числом пользователей различными способами. FRACAS повышает безотказность на всем протяжении стандартного жизненного цикла (этапы цикла показаны на рис. 1).
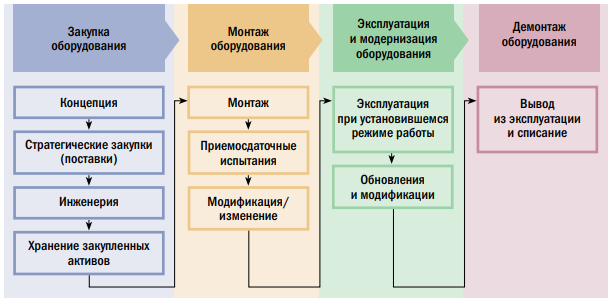
База данных системы FRACAS непосредственно связана со следующими объектами:
- Отчеты по отказам.
Посредством сбора и регистрации информации корректирующего технического обслуживания данные консолидируются в центральной системе регистрации данных; также отказы ранжируются с точки зрения их критичности и серьезности последствий. - Анализ отказов.
Подробное рассмотрение отчетов по отказам выполняется для получения из базы данных исторических данных обо всех связанных или похожих отказах. - Корректирующие действия.
После выявления коренных причин каждого отказа разработка корректирующих действий позволяет обратиться к проблеме совершенствования оборудования.
2. Количественные показатели отказов на основе статистического анализа
Количественный анализ должен использоваться для «взвешивания» отказа, чтобы получить понимание его важности и распределения во времени. Потенциальный и функциональный отказы должны измеряться с помощью инструментов статистики для оценки их влияния на производственную деятельность. Статистическое управление процессом (Statistical Process Control, далее — SPC, ГОСТ 11462-1-2007) позволяет пользователю непрерывно отслеживать, анализировать и контролировать процесс. SPC основывается на понимании вариации и ее влияния на результат любого процесса. Вариация — это величина отклонения от проектного номинального значения. Если мы рассматриваем отказ (Y) как функцию различных переменных (X1, 2, n), то он может быть представлен следующим образом:
Y = F(X).
Если нам известны вариации, вызванные различными переменными X, тогда с помощью SPC возможно в первую очередь отслеживать переменные X. Используя SPC, мы делаем попытку управлять критическими переменными X для контроля отказа Y. Для получения эффективного результата мы должны быть способны определить «несколько критически важных» переменных X и взять их под контроль для достижения требуемого результата по отказу Y.
Y может быть охарактеризован следующим образом: зависимость; результат; эффект (следствие); симптом; мониторинг. Переменные X1,…Xn могут быть охарактеризованы следующим образом: независимые; вход; причина; проблема; контроль (управление).
SPC главным образом используется для воздействия на нерегулируемые процессы, но также он применяется для слежения
за согласованностью процессов производства продуктов и услуг. Основной инструмент SPC — это контрольная диаграмма (Control Chart), графическое представление специфичных количественных показателей входов или результатов процесса. На контрольной диаграмме эти количественные показатели сравниваются с правилами принятия решений, вычисленными на основе вероятностей фактических замеров показателей процесса.
Сравнение правил принятия решений и данных показателей выявляет любые необычные вариации в процессе, которые могут
указывать на наличие проблем. Затем вычисляется среднее квадратичное отклонение, и две дополнительные линии добавляются на диаграмме.
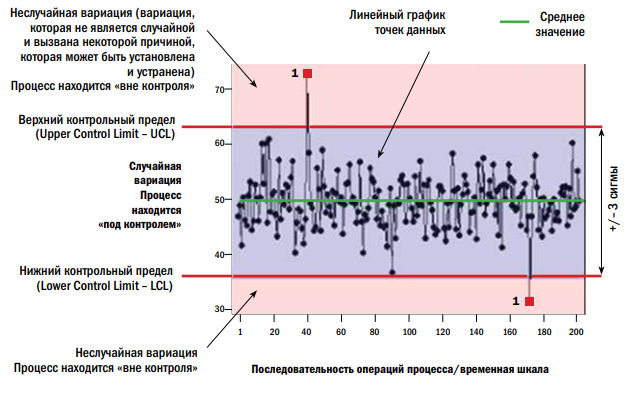
Как показано на рис. 2, эти линии размещены на расстоянии, равном +/- 3 средних квадратичных отклонения от среднего, и называются они «верхний контрольный предел» (UCL) и «нижний контрольный предел» (LCL) соответственно.
Сравнение правил принятия решений и данных показателей выявляет любые необычные вариации в процессе, которые могут
указывать на наличие проблем. Затем вычисляется среднее квадратичное отклонение, и две дополнительные линии добавляются на диаграмме.
Как показано на рис. 2, эти линии размещены на расстоянии, равном +/- 3 средних квадратичных отклонения от среднего, и называются они «верхний контрольный предел» (UCL) и «нижний контрольный предел»
(LCL) соответственно.
Диаграмма содержит три зоны.
- Полоса между линиями верхнего и нижнего контрольных пределов называется зоной случайной вариации.
- Полоса выше линии верхнего контрольного предела является зоной неслучайной
вариации. - Другая зона неслучайной вариации находится ниже линии нижнего контрольного
предела.
Контрольные диаграммы графически выделяют точки данных, которые не вписываются в нормальный уровень ожидаемой вариации. Математически это определяется как данные, отстоящие от среднего на величину, большую чем +/- 3 средних квадратичных отклонения. Контрольные диаграммы обеспечивают две основные функции: во-первых, это привязанная ко времени информация о показателях процесса, что делает возможным отслеживать события, влияющие на процесс, и, во-вторых, это предупреждение при возникновении неслучайных вариаций.
Это обычная практика, что уровень неслучайной вариации определяется как +/–3 средних квадратичных отклонения от среднего. Рассматривая рис. 3, мы должны принимать во внимание, что в области ниже кривой, в соответствии с базовой статистикой, значения +/-1 среднее квадратичное отклонение составляют 68% от распределения, +/–2 — 95% и +/–3 — 99,7%.
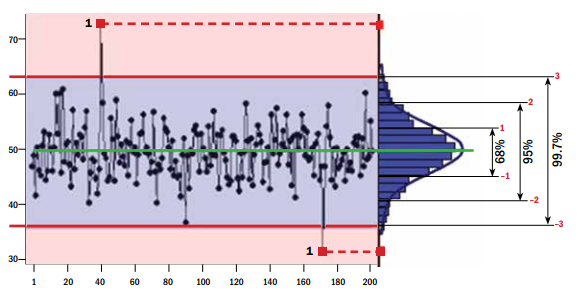
C точки зрения вероятности мы понимаем, что результат процесса будет иметь вероятность 99,7% попасть в диапазон +/- 3 средних квадратичных отклонения и только 0,3% вероятности (100 — 99,7), что точки данных будут за пределами диапазона +/- 3 средних квадратичных отклонения.
Поскольку мы говорим о двух зонах, одна зона выше трех средних квадратичных отклонений, другая ниже, то мы должны разделить 0,3% на два, что означает только 0,15% вероятности, что точка находится в одной из зон либо выше линии UCL, либо ниже линии
LCL. Это очень маленькая вероятность по сравнению с вероятностью в 99,7% того, что точка данных будет находиться между линиями UCL и LCL. То есть должно случиться что-то из ряда вон, чтобы точка данных была настолько далека от среднего: что-то вроде изменения деятельности профилактического обслуживания, ошибки оператора оборудования и т.д.
Применение SPC к потенциальным и функциональным отказам
Не всякая остановка оборудования может быть связана с потенциальным отклонением или отказом или функциональным отказом, и поэтому нам необходимо установить пределы для номинальных значений, чтобы понимать, следует ли считать остановку оборудования отказом или нет. При эксплуатации оборудования мы можем сталкиваться как с потенциальными, так и с функциональными отказами.
Потенциальные отказы могут рассматриваться как переменные, зависящие от мониторинга состояния, следовательно, могут быть определены такие показатели, как размер, вес и их единицы измерения. И наоборот, функциональный отказ выражает несоответствие или недоступность (отсутствие готовности) оборудования для производственной деятельности.
В этом случае SPC (статистическое управление процессом) использует атрибуты, которые обычно применяются к оценке общего качества продукции. Иными словами, переменные оцениваются при подсчете атрибутов.
Неслучайные вариации — это проблемы, которые возникают периодически. Примерами неслучайных вариаций являются ошибки операторов, неисправные инструменты, погрешность настроек оборудования.
На неслучайные вариации приходится от 5 до 15% проблем качества. Связаны они с фактором, «проскальзывающим» в процесс, вызывая нестабильные и непредсказуемые вариации. В результате устранения неслучайных вариаций мы должны получить процесс, который находится под статистическим контролем.
3. Распределение отказов
Использование исторических данных показателей работы оборудования обычно предполагает, что эти показатели будут моделировать текущие показатели. Таким образом, наилучшим способом использования этой информации для предсказания отказов является разумное применение предопределенных пределов сигнализации. На основе анализа множества данных отказов механических групп общая картина отказов принимает форму, показанную на рис. 4.
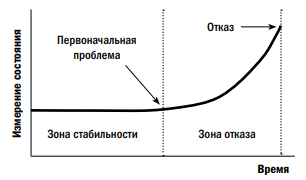
В стабильной зоне результаты измерений просто колеблются вокруг среднего значения.
Когда показатели начинают отклоняться от этих значений, становится очевидным, что проблема существует, а оборудование вошло в зону отказов. Установка объективных пределов сигнализации достигается с помощью теории SPC таким образом, что при выходе показателей мониторинга состояния за заданные пределы (обычно устанавливаемые в размере трех средних квадратичных отклонений от среднего) состояние регистрируется как нестабильное, и эксплуатация оборудования входит в обозначенную зону отказов. Каждая зона определяется в зависимости от того, находится ли значение показателя внутри или снаружи пределов сигнализации. С учетом этого очевидно, что данные состояния работают как переключатель или сигнал «разрешен/запрещен». Тем не менее для дальнейшего использования данных состояния также вводится модель зоны возникновения отказа (см. рис. 5).
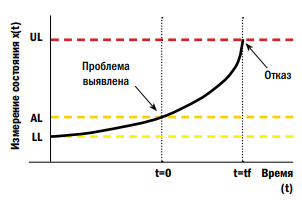
Состояние отказа начинается у самого нижнего предела (Lower Limit — LL), который является средним значением состояния в зоне стабильности.
Показатель состояния X(t) увеличивается до тех пор, пока не выявляется пересечение им предела сигнализации (Alarm Limit — AL).
Впоследствии в некоторый момент времени t = tf, достигается верхний предел (Upper Limit — UL), когда должна быть выполнена инспекция оборудования, или же оно должно быть выведено из эксплуатации. Изучение статистических данных фактических примеров отказов выявило, что диаграмма развития отказа может быть аппроксимирована экспоненциальной кривой. Значения LL и AL получают на основании SPCмоделирования стабильной зоны. Оценка значения UL является более проблематичной, так как это максимально возможный уровень, который может достичь оборудование до возникновения фактического отказа. Время tf получается из анализа надежности (безотказности) предыдущих отказов.
4. Определение интервала между задачами
Поскольку, как показано на рисунке 6а, интервал проверок основывается на периоде времени от точки потенциального отказа до точки функционального отказа, можно разработать кривую, отображающую время реализации отказа от его зарождения до функционального отказа. Этот временной период известен под названием «время от зарождения» (Time from onset — Tos).
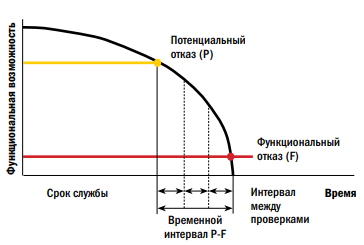
Рисунок 6б представляет пример; и точка на наклоне кривой, в которой проявляется физический симптом (потенциальный отказ), является началом периода Tos. Период Tos является максимально возможным временем интервала проверок. Чтобы проверка для выявления надвигающегося отказа гарантировано происходила между появлением потенциального и функционального отказа, интервал проверок должен быть короче периода Tos.
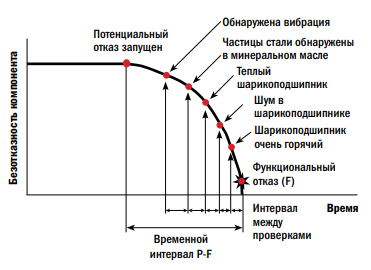
Если инспекция не выявляет и не корректирует механический износ или симптом, то до возникновения функционального отказа может иметь место по меньшей мере еще одна проверка.
Именно по этой причине для критических деталей оборудования, отказ которых может обуславливать риски безопасности пищевых продуктов, интервал проверки был установлен равным 1/3 или 1/4 от величины временного периода Tos.
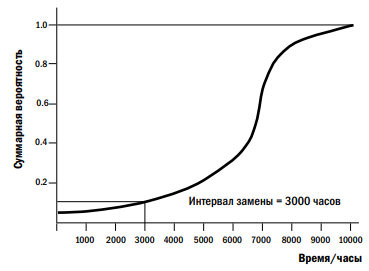
Планирование замены или задачи капитального ремонта было упражнением, основанным на кривой, отображенной на рисунке 7, и обозначающей кумулятивную вероятность отказа конкретного компонента при разных сроках службы. Поскольку вероятность отказа возрастает по мере увеличения возраста компонента, интервал между задачами выбирался для обеспечения приемлемой вероятности отказа. В данном случае решение о замене компонента происходит в момент сразу после 3000 часов эксплуатации, где вероятность отказа превышает 0,15. Если имеющиеся данные показывают, что отказы равномерно распределены вокруг среднего значения, то для календарного планирования интервалов технического обслуживания может использоваться средняя наработка до отказа (MTBF).
5. Качественный анализ отказов
Сразу после определения с помощью статистического анализа различных типов отказов и определения весов потенциальных и функциональных отказов мы готовы перейти к их качественному анализу.
Использование различных инструментов качества обусловит четкое понимание на всех уровнях: связи, существующие между причинами и последствиями; обоснования каждой причины; связь, существующая между каждой причиной и глобальным контекстом
оборудования и производства; логическая последовательность событий, приводящих к отказу. Ниже предлагается список некоторых инструментов качества, обычно используемых для выполнения качественного анализа отказов.
1. Анализы дерева отказов и «чем отличается»
Использование анализа дерева отказов (Fault Tree Analysis — FTA) создает связь между различными видами отказов и конкретными последствиями. Исследование для определения причин, лежащих в основе несоответствия системным требованиям, приводит к идентификации коренных причин несоответствия, требуемых для определения корректирующих действий FTA — графический метод определения всех причин потенциальных отказов. Дерево отказов начинается с верхнего неблагоприятного события, являющегося системным видом отказа, для которого выполняется попытка идентифицировать все потенциальные причины.
На рисунке 8 показан простой пример применения анализа к плохой упаковке поперечного запечатывания для указания того, как различные причины конкретных отказов (потенциальных или функциональных) могут быть связаны вместе. Центральный ряд отображает реальную причину, которая вызывает этот отказ (отказ и последствие), а боковые ряды отображают скрытые причины или человеческие ошибки. Этот метод позволяет связать причины и последствия в логической последовательности, отображая единое представление динамики событий, которые приводят к критическим отказам. Более сложные деревья отказов могут быть разработаны с помощью логических элементов OR, AND и других операторов, а также инструментов объединения причин потенциальных отказов и существующих между ними связей. После создания дерева отказов, которое связывает причины потенциальных отказов с их последствиями в логической последовательности, становится необходимым реализовать некоторые дополнительные методы для лучшей идентификации истинных причин отказов.
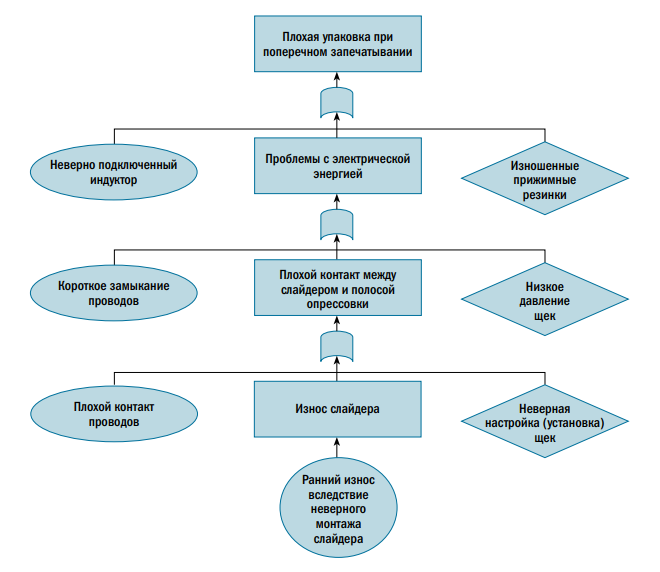
Анализ «чем отличается» — это простой метод определения изменений, которые могли вызвать отказ. Главная предпосылка этого анализа заключается в том, что система работала в штатном режиме до возникновения отказа; следовательно, что-то должно было измениться, чтобы вызвать отказ.
Потенциальные изменения учитывают анализ всех взаимодействующих факторов, таких как проект (структура) системы, практики и процессы производства, смена поставщиков, смена операторов оборудования, изменение качества партий технических средств и другие факторы. По мере выявления изменений они должны оцениваться в отношении выявленных причин потенциальных отказов.
2. Анализ первопричин и выявление причин
Использование этих двух методов привязывает проблемы к глобальному контексту производственной организации. Анализ основных причин (или первопричин) основывается на трех основных вопросах:
- В чем проблема?
- Почему это произошло?
- Что будет сделано для предотвращения повторения этого в будущем?
Анализ основных причин (RCA) начинается от результата или от симптома проблемы, связывая их с глубинными причинами. Поскольку начало исследования отдельной проблемы не обязательно отражает глобальный характер отказа, анализ выявления причин определяет проблемы в контексте общих целей производства. Карта причин (Cause Map) визуально организует результаты любого исследования в виде прямоугольников (последствий) слева с причиной справа. Причина, в свою очередь, представляет собой последствие другой причины, снова размещенной правее. По этой причине каждый прямоугольник на карте причин можно рассматривать одновременно и как причину, и как последствие. Движитель анализа выявления причин включает вопросы «почему», которые связывают вместе цепочку событий.
Схема, изображенная на рис. 9, представляет собой схему очистки, где красный кружок — это клапан, который позволяет жидкому пищевому продукту протекать, в то время как наполняющее оборудование (A) эксплуатируется, а оборудование (B) в состоянии прочистки.
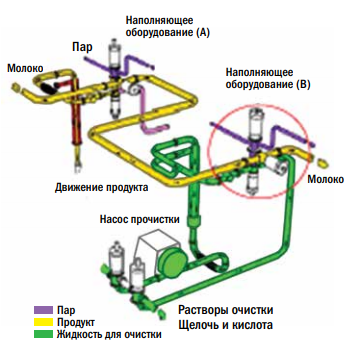
Было выявлено, что из-за отсутствия надежной программы технического обслуживания чистящие растворы попадают в продуктовые трубы, так как клапаны продукта и очистки наполняющего оборудования (B) не закрываются корректно. Небольшие утечки кислотных и щелочных растворов вступают в контакт с жидким пищевым продуктом, если изношенные тарелки клапанов не меняются в надлежащее время.
Диаграмма RCA на рис. 10 определяет различные причины, которые создают проблемы в части безопасности продукта, эффективности оборудования и производственных затрат.
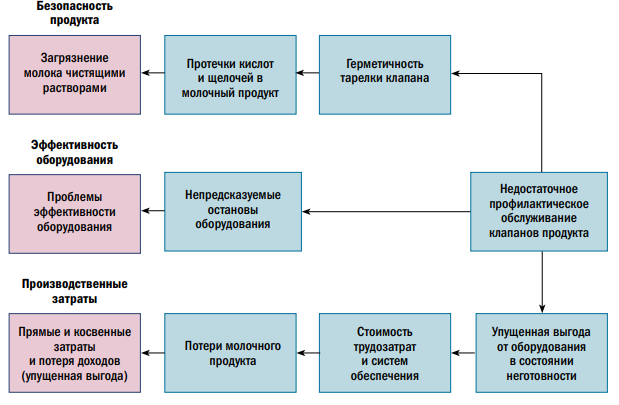
Связь, существующая между различными причинами и последствиями, позволяет увидеть четкую картину, отображающую последовательность событий и результатов по разным объектам. Эти диаграммы, помимо их использования для целей устранения отказов, могут быть особенно эффективны при использовании в качестве материалов для обучения.
3. Исикава и его диаграмма причинно-следственных связей («рыбий скелет»)
Метод помогает визуально выявлять проблему и все возможные причины. Он позволяет выделять причины проблем, группируя их по основным семействам: машины, методы, материалы, измерения, среда, люди… Исикава начинает с формулировки проблемы,
а затем разделяет возможные причины по отдельным категориям, которые ответвляются, как кости скелета рыбы.
Этот дополнительный инструмент анализа первопричин единовременно определяет одну проблему и находит причины, позволяя получить глобальную картину причин, сгруппированных по категориям. Этот метод не показывает взаимосвязи причины и следствия в ее динамическом развитии, как это делает RCA, но он создает каталог причин, лежащих в основе каждой проблемы, для отображения различных причин, разделенных по семействам. Поскольку, например, проблема обучения, находящаяся в группе «персонал», может привести к тому, что оператор совершит ошибку, что в результате приведет к отказу оборудования, находящегося в группе «оборудование», необходимо изыскать данные, которые помогут связать диаграмму Исикавы с RCA.
На рис. 11 отображена диаграмма Исикавы в приложении к механизму избыточной нагрузки разгрузочного устройства расфасовочного оборудования. Различные причины, которые приводят к превышению допустимой нагрузки, перечислены в основных ветвях: материалы, методы, оборудование (машины) и измерения (показатели).
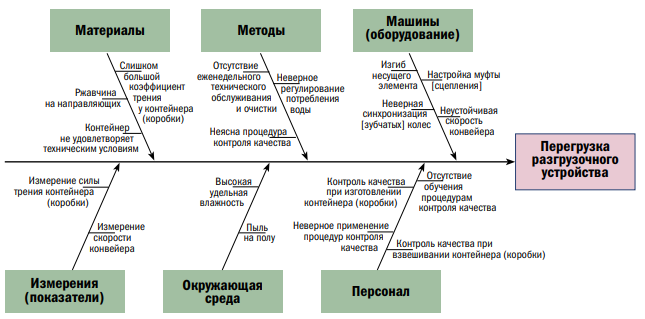
В каждой ветви мы перечисляем причины, которые способствуют возникновению проблемы, которая в свою очередь является отдельным следствием, и эти причины группируются в основных ответвлениях. Этот метод работает с отдельным следствием и всеми потенциальными причинами, лежащими в основе этого следствия. Несмотря на то, что это не динамическое представление развития причин и следствий, метод должен использоваться как дополнительный инструмент для отображения всех причин, создающих отдельное (единичное) следствие. В заключение необходимо отметить, что анализ дерева отказов начинается с верхнего неблагоприятного события, являющегося системным видом отказа, для которого делается попытка идентифицировать все потенциальные причины и затем связать все потенциальные причины в логическое дерево, используя события и логические шлюзы. Далее анализ дерева отказов и диаграмма Исикавы позволяют идентифицировать потенциальные причины, которые создают отказ, показывая причины и следствия и группируя их в семейства.
4. Метод пяти «почему»
Метод пяти «почему» является дополнительным инструментом для диаграммы Исикавы. Он помогает начать с конечного результата, позволяя поразмыслить над тем, что вызвало это, и задать вопрос пять раз. Этот простой, но очень эффективный подход к решению проблемы способствует глубоким размышлениям через вопросы и может быть быстро адаптирован и применен к большинству проблем.
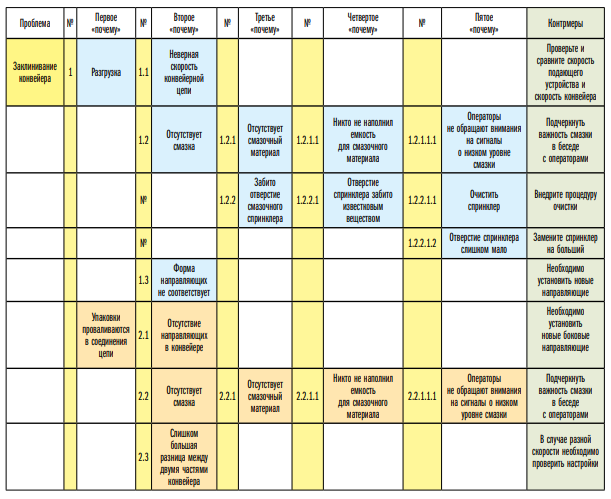
Рисунок 12 просто показывает каждое «почему» как дверь, которая должна быть открыта, чтобы войти в определенный контекст для выяснения его содержимого.
Для эффективного использования метода пяти «почему» существуют три ключевых элемента:
- Точные и полные формулировки (изложение) проблем;
- Абсолютная откровенность при ответах
на вопросы; - Твердое намерение разобраться в проблемах и разрешить их.
Метод пяти «почему» становится более эффективным, если применяется командой. Выполняется он в пять основных шагов.
- Соберите команду, разработайте признаваемую всеми формулировку проблемы и решите, требуется ли участие кого-либо еще для разрешения проблемы.
- Задайте первое «почему» команде: «Почему возникает та или иная проблема?» Вполне вероятно, что вы получите три или четыре разумных ответа: запишите их все в презентационный блокнот или на доске.
- Задайте один за другим еще четыре «почему», повторяя процесс для каждой формулировки в блокноте или на доске. Размещайте каждый ответ рядом с его «родителем». Проработайте все возможные правдоподобные ответы. Вы определите коренную причину, когда следующий ответ на вопрос «почему» не даст вам дополнительной полезной информации.
- Ищите системные причины проблемы среди дюжины ответов на последний вопрос «почему». Обсудите их и остановитесь на наиболее вероятной системной причине. Подведите итоги собрания команды и покажите результат другим сотрудникам, чтобы убедиться, что и они видят логику в выполненном анализе.
- После установления наиболее вероятной коренной причины проблемы и получения подтверждения логичности анализа разработайте соответствующие корректирующие действия для удаления этой коренной причины из системы.
Чтобы сделать использование этого инструмента эффективным, не останавливайтесь на симптомах и не переходите к причинам более низкого уровня.
На рис. 12 показано применение этого метода к проблеме заклинивания конвейера. Каждая выявленная причина становится следствием многих других причин, и этот процесс заканчивается определением контрмер для предотвращения или устранения проблемы. Воронка отказов, изображенная на рис. 13, представляет собой результат, полученный с применением основных методов и приемов (качественных и количественных).
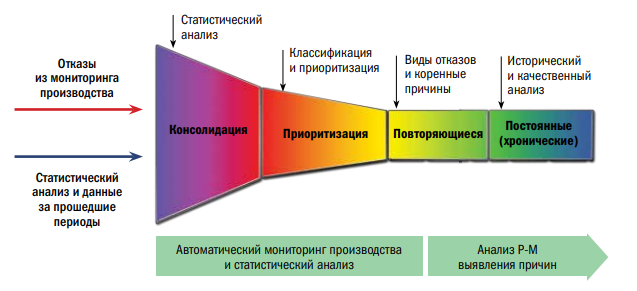
C помощью количественного анализа мы можем идентифицировать и консолидировать различные типы отказов в системе.
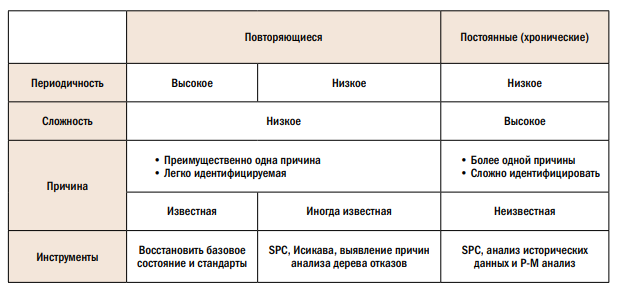
С помощью качественного анализа мы определяем взаимосвязи, существующие между причинами и следствиями в определенном контексте, и затем, как результат, мы способны приоритизировать и классифицировать отказы.
В таблице приведены краткие данные по повторяющимся и хроническим отказам с отображением их частоты, сложности и потенциальных причин, а также основные результаты их количественного и качественного анализов.
Журнал Prostoev.NET № 1(10) 2017
Prostoev.NET, по материалам западных публикаций


